

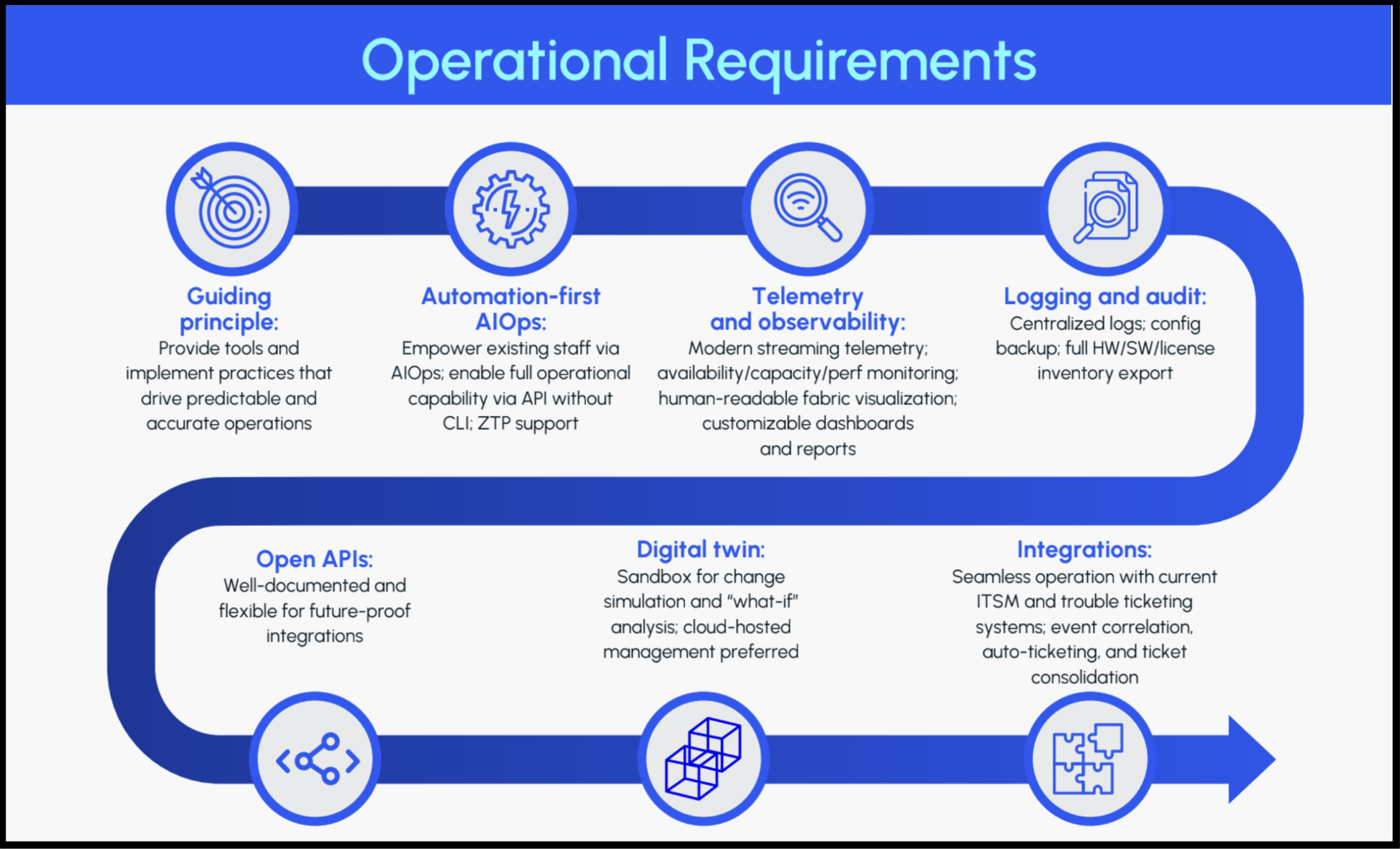
Designing a cutting-edge network is only half the battle – operating it efficiently and reliably is the other half, and maybe more. Modern data center networks demand a new operational mindset, one that leverages automation, artificial intelligence, and seamless integration with IT workflows. In the Operational Requirements section of The Modern Data Center Checklist infographic by Futurum Research, the focus is on exactly these capabilities: from automation-first principles and AIOps, to advanced telemetry, open APIs, digital twins, and IT integration. In this final post of the series, we explore why these operational requirements have become strategic priorities and how they are transforming day-to-day network management for IT teams and business leaders alike.
Automation-First and AIOps: From Manual to Autonomous
Gone are the days when network engineers could configure every switch and troubleshoot every issue by hand. The scale and complexity of modern data centers (often with thousands of devices and dynamic changes happening daily) have made automation a necessity. In a recent study by Futurum Research, fully 70% of organizations rated automated operations as an important factor for their next-gen networks. The reason is clear: manual processes simply can’t guarantee the speed or consistency that businesses now require. Automation, through scripts, orchestration platforms, infrastructure-as-code, and other evolving AIOps mechanisms, allows changes to be deployed rapidly and uniformly across the network. This improves agility – for example, deploying a new application environment might involve updating dozens of network devices, a task automation can accomplish in minutes versus days. Just as importantly, automation minimizes human error. Misconfigurations by humans remain a leading cause of outages, and removing this risk factor leads to more reliable networks. According to industry analysis, implementing network automation can significantly reduce costly errors and downtime, which in turn lowers operational expenses and total cost of ownership (TCO). Little wonder that half of IT leaders surveyed plan to invest in AI-driven automation tools specifically to reduce manual mistakes and boost reliability.

Building on basic automation, AIOps (Artificial Intelligence for Network and IT Operations) is emerging as a game-changer for network management. AIOps involves using machine learning and advanced analytics on the wealth of network data (logs, telemetry, alerts) to detect patterns and even predict issues before they occur. The goal is to transition from reactive troubleshooting to proactive, and eventually autonomous, network operations. Our checklist emphasizes empowering staff with AIOps and ensuring the network offers full API-driven control (no “CLI-only” limitations). This points to a future where network management systems can automatically pinpoint an outage cause or adjust configurations to prevent performance degradation – effectively an autonomous network “co-pilot” assisting the human operators. Many organizations are moving past the experimental phase here: they’re implementing AI-powered monitoring and event correlation tools as we speak. The survey data shows this clearly – two-thirds of companies already use automated monitoring/alerting, and a majority use config automation or infrastructure-as-code, laying the groundwork for AIOps. The strategic impact is significant: AIOps can augment stretched IT teams, mitigate the skills gap in networking automation (which 54% of organizations say is a major hurdle), and ultimately keep the network more stable. Leaders are recognizing that adopting automation and AIOps is key to keeping up with the complexity and speed of modern infrastructure.
Telemetry and Observability: Seeing is Knowing
Underpinning both automation and AIOps is the need for rich telemetry and observability from the network. You can’t automate or intelligently optimize what you can’t adequately monitor. That’s why modern data center networks are embracing streaming telemetry, granular monitoring, and advanced visualization as core requirements. Instead of periodic, coarse checks (like traditional SNMP polling), streaming telemetry continuously pushes data on link and system performance, traffic flows, latency, buffer usage, and more to monitoring systems in real-time. This data firehose enables a level of observability that simply wasn’t possible in legacy networks.
From a strategic standpoint, improved observability translates directly into better uptime and performance for the business. Network teams can catch anomalies faster – for example, detecting a traffic spike or microburst congestion on a critical link and rerouting proactively. Human operators benefit from “human-readable fabric visualization [and] customizable dashboards” as noted in the checklist, meaning modern Network Operations Center (NOC) software can display the state of the network in intuitive maps and graphs, often overlaid with service or business context. This helps IT and business stakeholders alike understand how the infrastructure is behaving at any moment. There’s also a feedback loop here: detailed telemetry is the fuel for AIOps algorithms. The more high-quality data available (flows, error rates, device sensor readings, etc.), the better AI models can learn the network’s baseline behavior and spot deviations indicative of faults.
It’s telling that one of the big obstacles to automation that leaders cited is the “inability to monitor the network’s current state versus its desired state” (46% of respondents). In other words, without good observability, it’s hard to even trust automation (since you can’t easily verify that what you intended is what’s actually happening). Modern networks address this by building closed-loop monitoring – every automated change is immediately validated by automated tests (e.g. pre- and post-checks) and telemetry and traffic patterns. This shift to telemetry-driven assurance means higher confidence in changes and faster incident resolution when things do go wrong. For businesses, that translates to more predictable performance and fewer service disruptions, delivering on the promise of reliability we discussed earlier. In summary, observability has graduated from a technical nice-to-have to a strategic must-have in network operations. It provides the visibility required for informed decision-making and automated control, much like instrumentation in a modern airplane enables autopilot and swift interventions.
Open APIs and Integration: Breaking Down Silos
Modern IT environments are highly integrated ecosystems, and the network can no longer live in a silo. This is why open APIs and seamless integrations are highlighted as key operational requirements in the checklist. An API-first approach to networking means every function of the network (provisioning a VLAN, retrieving performance data, applying a policy change) is accessible programmatically. This is essential for plugging the network into broader IT workflows. For instance, developers might trigger network changes via a CI/CD pipeline when deploying a new application, or an IT Service Management (ITSM) platform like ServiceNow might automatically create a network ticket and, through integration, pull diagnostic info via APIs. In the survey, ease of integration was nearly as important as reliability itself for network decision-makers. The message is clear: a network that can’t integrate with other systems will hinder business agility and drive up operational costs.

Open APIs also future-proof the network by allowing “network as code” practices. Organizations can develop custom tools or scripts that talk to these APIs to achieve bespoke functionality or reports tailored to their business needs. The checklist points to integrations with current ITSM and incident management systems, event correlation, and even automated ticketing – all of which are enabled by exposing network capabilities through well-documented APIs. An example of this in action is integrating network state data with a monitoring platform to correlate network events with application performance issues, so that the right team gets alerted with the full context. The strategic benefit is that the network becomes a more collaborative component of IT operations: network teams, server teams, security teams, and developers can all work together through integrated systems, rather than throwing requests over the wall. This integration reduces friction and speeds up both troubleshooting and new deployments.
Moreover, support for openness at the API level often mirrors openness at the product level – many modern network solutions are embracing open-source initiatives and developer support. This openness is critical for business decision-makers because it means greater flexibility and avoiding getting “locked in” to a single vendor’s ecosystem. In a fast-changing tech landscape (think about the rise of containers, Kubernetes, multi-cloud, etc.), the ability to integrate your network with whatever new platform comes along is a strategic insurance policy. The bottom line is that networks with open APIs and strong integration capabilities empower organizations to operate with the speed and coordination that digital business demands.
Digital Twins and Proactive Planning
One of the more forward-looking operational trends in data center networking is the use of network digital twins. A digital twin is essentially a virtual replica (e.g., a model) of the network’s topology, configurations, and even traffic behaviors, used for simulation and testing. While still an emerging practice, our research found over a quarter (27%) of organizations plan to invest in a digital twin for their network to enable real-time monitoring, predictive maintenance, and optimization. The reason digital twins are gaining attention is their potential to vastly improve how changes and new designs are introduced – by testing “what-if” scenarios in a risk-free environment before touching the production network.
Imagine being able to simulate a major network upgrade or a new configuration change in software and foresee its impact, catching errors or performance issues in advance. Gartner analysts note that configuration errors are a major cause of network downtime, and they estimate that leveraging network digital twins to model changes before deployment could reduce unplanned outages by up to 70%. That is a staggering reliability improvement, which translates directly into business resilience. By using a sandboxed digital twin, network engineers can experiment with different routing topologies, test failover scenarios, and validate security policies with no risk to the live environment. Early adopters have reported finding failure modes in the twin that were previously unknown in the real network – insights that allowed them to strengthen the design before an issue ever occurred.
Digital twins also facilitate cross-team collaboration and better planning. For example, application teams can use the twin to gauge whether the network can handle a new deployment’s load, or security teams can simulate cyberattacks to see if the network segmentation holds up. While the technology is new and not yet mainstream, it aligns with the broader trend of proactive operations. Rather than reacting to outages or slowly adapting to growth, organizations are striving to anticipate and optimize future network states. Business leaders appreciate this because it de-risks digital transformation initiatives – you have a virtual safety net to ensure network reliability as you innovate.
In conclusion, the operational requirements of automation, AIOps, observability, open APIs, and digital twin capabilities are all about achieving accurate, predictable, efficient outcomes in network operations. They represent a shift from manual, ad-hoc operations to systematic, software-driven operations. This shift is happening because the cost of not doing so is simply too high: human errors, slow responses, and siloed tools translate to downtime and lost opportunities. Conversely, an automation-first, intelligently observant network operations model yields the dual benefits of higher reliability and lower operating costs – precisely the alignment of IT goals and business goals that modern enterprises seek. As you assess your own data center network, consider these emerging requirements not as wish-list items but as crucial components of a strategy for resilience and agility.
The Modern Data Center Network Checklist infographic ties all these operational elements together, and it serves as a handy visual reminder that building a great network is about more than hardware and protocols – how you run it day-to-day to deliver value back to the business is becoming more and more critical.
This blog post is number 3 in a series of 3. To see the other posts, visit: https://techstrong.it/category/sponsored/modern-dcn-checklist-blog-series/
